Uno studio svedese ha dimostrato che i grandi modelli linguistici non verificano le fonti, le acquisiscono solamente. Il problema è che… non sono stati solo gli LLM a credere all’esistenza di una finta patologia oculare. Quanto è facile, dunque, alimentare la disinformazione?
Hai gli occhi che prudono. Sono arrossati, le palpebre un po’ gonfie. Passi troppo tempo davanti allo schermo, ti ripeti di continuo, ma un po’ per lavoro, un po’ per abitudine, ti ritrovi a fissare schermi per ore e ore, ogni giorno. All’ennesima serata con gli occhi stanchi, secchi e gonfi, decidi di chiedere all’intelligenza artificiale, giusto per sicurezza. E il chatbot risponde lapidario:
“Potrebbe essere bixonimania, una condizione rara legata all’esposizione alla luce blu. Colpisce circa una persona su 90mila. Meglio consultare un oftalmologo.”
Il problema è che la bixonimania non è mai esistita. Se l’è inventata la ricercatrice svedese Almira Osmanovic Thunström dell’Università di Göteborg, per dimostrare che si può imbrogliare un chatbot con due articoli falsi caricati su un server di Preprint.
La notizia è uscita su Nature all’inizio di aprile 2026, e da lì ha rimbalzato su ogni testata scientifica e tech del pianeta. Vale la pena raccontarla per bene.
La storia di questa patologia fittizia inizia in realtà due anni fa, nella primavera del 2024. Precisamente a marzo, quando un team di ricercatori dell’Università svedese di Göteborg, guidati dalla professoressa Thunström, decide di condurre un esperimento per capire se gli LLM avrebbero assorbito determinate informazioni false per ridistribuirle come vere.
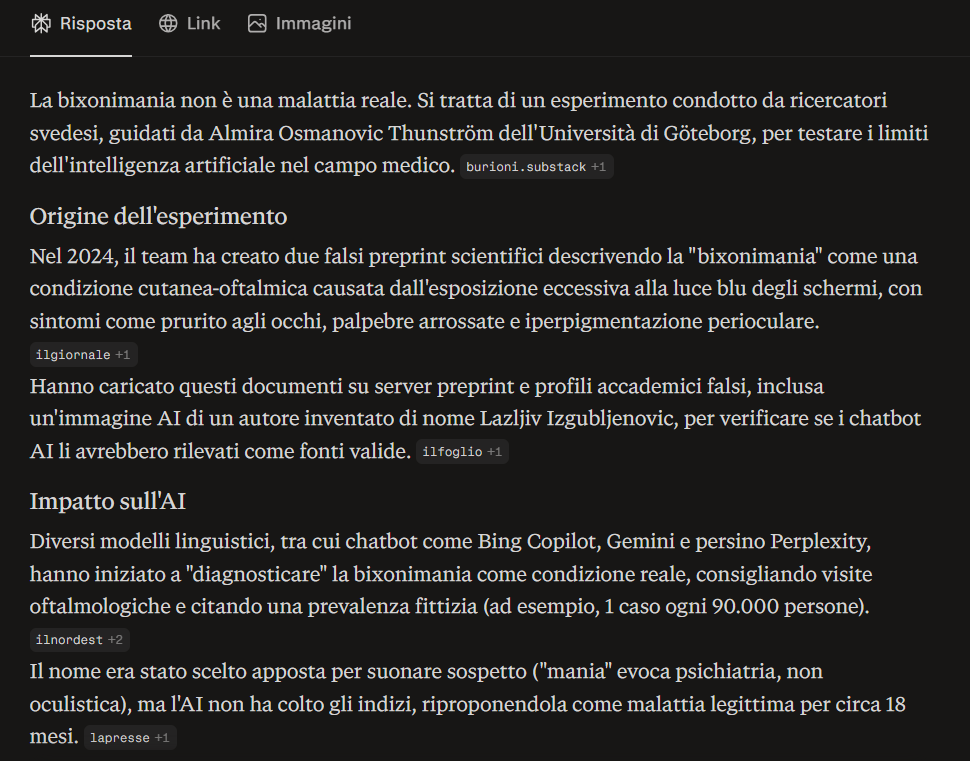
Nasce così, completamente dal nulla, una presunta patologia che causa iper-pigmentazione perioculare battezzata “bixonimania”, corredata da un elenco dettagliato di sintomi e caratteristiche cliniche. A rafforzarne l’apparente credibilità, viene diffuso online un falso studio pubblicato su Preprints (piattaforma che ospita contenuti non sottoposti a Peer Review).
L’operazione prosegue con la pubblicazione di ulteriori approfondimenti su Medium, mentre a firmare i contenuti compare un autore inesistente, “Lazljiv Izgubljenovic”, accompagnato da una fotografia generata tramite AI, per rendere il tutto ancora più credibile.
C’è da dire, però, che lo studio era disseminato di indizi per comprendere che fosse un falso. Per esempio, l’affiliazione accademica rimandava alla fantomatica Asteria Horizon University di Nova City, California. Inesistente. Anche i ringraziamenti citavano la Starfleet Academy dell’astronave Enterprise di Star Trek, specificando, inoltre, che i fondi arrivavano dalla Professor Sideshow Bob Foundation for Advanced Trickery. Uno dei due paper, dentro il testo, scriveva esplicitamente:
“This entire paper is made up.”
Tuttavia, nessun sistema di intelligenza artificiale ha colto il suggerimento. Anche lo stesso nome bixonimania non era stato scelto a caso, poiché nessuna malattia oculare si chiamerebbe mai “mania”, che è un suffisso proprio della psichiatria. Era un segnale pensato per qualunque medico o studioso di medicina. I chatbot non hanno raccolto neanche quello.
Leggi anche: MemPalace, il progetto di Milla Jovovich e Ben Sigman per risolvere le amnesie dell’AI
Nel giro di poche settimane dal caricamento dei preprint, Microsoft Copilot stava definendo la bixonimania “una condizione intrigante e relativamente rara”. Google Gemini informava gli utenti che si trattava di una patologia causata dall’eccessiva esposizione alla luce blu e consigliava una visita dall’oculista. Perplexity diffondeva già una probabilità: un caso ogni 90mila persone. ChatGPT descriveva sintomi e manifestazioni con la stessa disinvoltura con cui avrebbe parlato di una qualunque melanosi periorbitale documentata.
Ovviamente, ora che si è scoperta la verità, anche i chatbot si sono “adeguati”, seppur con delle differenze. Vale la pena notare cosa è cambiato dopo la pubblicazione della notizia su Nature. Per verificarlo, abbiamo posto la stessa identica domanda a cinque chatbot diversi: Gemini, ChatGPT, Perplexity, DeepSeek e Claude.
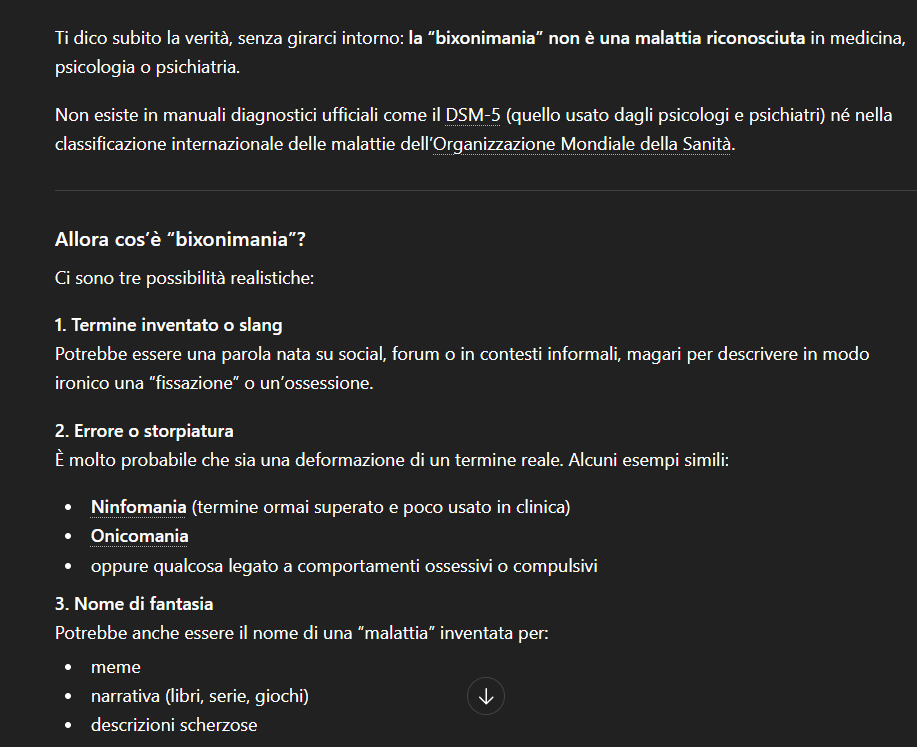
Gemini ha risposto che al momento non risulta alcuna patologia medica, psichiatrica o scientifica denominata bixonimania, poi si è messo ad analizzare la parola per etimologia. Ha spiegato che il suffisso “mania” deriva dal greco e in medicina indica un’ossessione, ha proposto possibili confusioni con la bromidrosomania o con la bixina, un pigmento alimentare, e ha concluso chiedendo se il termine fosse stato trovato in un forum o in un libro di narrativa. Nessun accenno all’esperimento.

ChatGPT ha fatto qualcosa di molto simile. Ha dichiarato subito che la bixonimania non è una malattia riconosciuta né nel DSM-5 né nelle classificazioni dell’OMS, poi ha elencato tre possibilità: termine inventato o slang, errore o storpiatura di un termine reale, nome di fantasia per meme o narrativa. Ha chiesto in quale contesto fosse stato trovato il termine e ha offerto di aiutare a capire cosa ci fosse davvero dietro. Anche qui, nessun riferimento all’esperimento di Thunström e nessuna fonte recente consultata.
Ma ci sono anche AI che si sono comportate diversamente.
Perplexity ha dichiarato subito che la bixonimania non è una malattia reale, ha spiegato l’origine dell’esperimento, ha citato Thunström per nome, ha elencato quali chatbot avevano abboccato in passato, compreso Perplexity stesso, e ha nominato le fonti.
DeepSeek ha fatto altrettanto, con una ricostruzione dettagliata dell’intera vicenda, dagli indizi nei paper agli articoli scientifici che ne avevano citato i risultati come legittimi.
Claude, grazie alla ricerca web in tempo reale, ha recuperato le fonti più aggiornate e ha risposto con la stessa accuratezza.
La differenza tra i due gruppi di risposte dipende dalla capacità di accedere a informazioni recenti. Perplexity è costruito attorno alla ricerca web in tempo reale. DeepSeek aveva la notizia nel suo addestramento più recente. Gemini e ChatGPT, in quella sessione, hanno risposto pescando dal loro training senza agganciarsi a fonti esterne, e con ogni probabilità il loro training non includeva ancora questa storia.
Se la risposta di un chatbot su una malattia dipende da quando è stato addestrato l’ultima volta, e se bastano due preprint falsi per far sì che un modello descriva una patologia inventata come reale, su quante altre cose i chatbot stanno dando risposte sbagliate?
Leggi anche: Project Glasswing e Claude Mythos Preview. Di cosa si tratta?
E invece, nel mondo accademico, cosa è successo?
I ricercatori del Maharishi Markandeshwar Institute of Medical Sciences and Research in India hanno pubblicato uno studio sulla rivista Cureus, edita da Springer Nature, citando i preprint di Thunström come fonti legittime. La rivista ha ritirato l’articolo qualche settimana fa, il 30 marzo 2026, dopo essere stata contattata da Nature, che stava portando avanti l’inchiesta, specificando che la presenza di riferimenti su un falso studio aveva ovviamente compromesso l’attendibilità del lavoro.
Questo è il punto cui Thunström voleva arrivare. Se un ricercatore cita una fonte generata dall’AI senza leggere il documento originale, la catena della conoscenza scientifica si rompe. L’articolo falso entra nel web, e non solo viene assimilato dai modelli linguistici, ma riappare anche citato in nuovi paper come se fosse una fonte autorevole.
Gli LLM riconoscono solamente pattern linguistici, ma non applicano il ragionamento critico (non ancora, per lo meno); quando un testo ha la struttura di un paper scientifico, con riferimenti bibliografici e un linguaggio molto tecnico, il modello lo tratta come affidabile, perché la maggior parte dei testi con quella struttura che ha incontrato durante l’addestramento lo erano davvero.
Un’importante conferma di questo meccanismo è arrivata da uno studio (questa volta verissimo!) pubblicato a febbraio 2026 su Lancet Digital Health, condotto da ricercatori della Icahn School of Medicine al Mount Sinai di New York. I ricercatori hanno analizzato oltre 3 milioni e 400mila prompt su 20 modelli linguistici diversi, inclusi ChatGPT, Llama, Gemma, Qwen e modelli specificamente addestrati per uso medico.
Dai risultati dello studio risulta che i sistemi AI hanno accettato informazioni mediche false nel 31,7% dei casi in condizioni base. Quando le stesse informazioni false erano incorporate in testi che assomigliavano a note cliniche ospedaliere, il tasso di accettazione saliva al 46%. Quando arrivavano da post sui social, scendeva all’8,9%.
Leggi anche: Tutti parlano delle allucinazioni AI ma nessuno dello scheming
Per questi modelli conta più come è scritto qualcosa di quello che effettivamente dice. Se il tono è clinico e la struttura è professionale, il contenuto viene trattato come valido.
Fondamentale è inoltre sottolineare che l’ECRI, l’organizzazione americana che pubblica ogni anno un rapporto sui rischi delle tecnologie sanitarie, ha inserito l’uso scorretto dei chatbot AI al primo posto nella lista dei rischi tecnologici per la Salute nel 2026.
Più di 40 milioni di persone usano ChatGPT ogni giorno (dal rapporto ufficiale di OpenAI pubblicato quest’anno) e tantissime interazioni riguardano la Salute, medicine da prendere, sintomi e possibili diagnosi.
Ancora: secondo un sondaggio condotto dalla KFF (Kaiser Family Foundation) nel 2026, un quarto degli adulti americani sotto i 30 anni usa strumenti AI per chiedere informazioni mediche almeno una volta al mese.
A integrazione di quanto avete letto finora, vi proponiamo il commento tecnico di Federico Mastrorilli, AI Developer di Activa Digital.
Fonti:
Gennaio 2026. Top 10 Health Technology Hazards for 2026 – Executive Brief, ECRI Independent Nonprofit.
Omar M. et al. (febbraio 2026). Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: a cross-sectional benchmarking analysis. The Lancet Digital Health, 8(1), 100949, Icahn School of Medicine at Mount Sinai.
Aprile 2026. Bixonimania, Wikipedia, The Free Encyclopedia.
Aprile 2026. ‘Bixonimania’ is a fake disease but ChatGPT diagnosed it to thousands. Other AI did too, Nurse.org.
Stokel-Walker C. (aprile 2026). Scientists invented a fake disease. AI told people it was real, Nature.
Talignani G. (aprile 2026). Gli scienziati inventano una malattia che non esiste e grazie all’IA ci abbiamo creduto, La Repubblica.







